El lado oscuro de la Inteligencia Artificial
Probablemente ya hayas experimentado lo que es quedarse embobado frente a YouTube o TikTok viendo un vídeo tras otro al seguir las golosas sugerencias que un algoritmo inteligente te estaba presentando. También es probable que al rato te hayas despertado del continuo de imágenes de la pantalla para descubrir con cierto sobrecogimiento cómo han volado las horas y cómo de bien te conoce el algoritmo. Y es que estos algoritmos pueden llegar a conocerte casi mejor que tus amigos, pareja o padres [1]. Es entonces cuando al pensar en la IA nos pueden surgir dudas acerca de nuestra privacidad, si es socialmente responsable o no desarrollar sistemas que sustituyan trabajos realizados por humanos o incluso preocuparnos sobre la supervivencia del ser humano como especie. Todos estos aspectos son ya objeto de discusión o al menos somos conscientes de su existencia.
Sin embargo, hay un problema de la IA del que NO somos del todo conscientes y que este artículo pretende dar a conocer: el alto consumo energético y los largos tiempos de computación que requiere la IA. Este incipiente problema amenaza la sostenibilidad de los servicios digitales de los que disfrutamos hoy en día haciendo que el incesante desarrollo de las tecnologías de la información sea cada vez más costoso para el medio ambiente. Pero tranquilidad, los físicos junto a los ingenieros sabemos cómo prevenir este problema. ¡Échale un ojo a este artículo para descubrir cómo!
¡La inteligencia artificial es muy ineficiente!
En términos energéticos, poner en marcha (o entrenar, según la jerga de los desarrolladores de IA) un algoritmo de IA puntero, como los que emplean Google o Facebook, puede llegar a emitir indirectamente a través de su consumo eléctrico tantos gases de efecto invernadero como cinco coches durante sus vidas útiles promedio [2]. Y es más, entrenar estos algoritmos requiere de centenares de ensayos de prueba y error hasta que se alcanza el funcionamiento deseado.
En cuanto al tiempo de computación, estos algoritmos no se entrenan en cuestión de segundos o minutos, como nos parecería natural teniendo en cuenta los tiempos de respuesta de los programas de uso cotidiano, sino que requieren de días e incluso de semanas de cómputo en grandes clusters de ordenadores [3].
Por poner un caso concreto, es habitual demostrar el potencial de la IA enfrentándola contra humanos en juegos de mesa como el ajedrez. La más reciente de estas batallas enfrentó a la IA de Google, AlphaGo, contra el campeón mundial del juego de mesa chino Go, el señor Lee Sedol. El resultado final fue que la máquina ganó al humano, lo que es considerado otra hazaña más en el historial de éxitos de la IA. Sin embargo, ¡este combate no era justo energéticamente! Mientras que la máquina estaba consumiendo 10 millones de vatios de potencia, el señor Lee consumía apenas 20 vatios (incluso teniendo en cuenta la taza de café que se estaba tomando según se ve en la Figura 1). Esta diferencia en consumo evidencia la baja eficiencia energética de la IA. En breve explicaremos cómo y dónde se origina esta ineficiencia.

Figura 1: Comparativa de consumo energético en las partidas del juego de mesa Go entre la IA de Google DeepMind, AlphaGo, y el campeón mundial Lee Sedol. Extracto de la grabación [4].
El origen de la ineficiencia de la IA
Ahora sí, vamos al origen de la ineficiencia de la IA. Primero vamos a comprender cómo funciona la IA a nivel de algoritmos, o sea, el software; y luego veremos cómo se implementan estos algoritmos en físico, es decir, el hardware.
¿Cómo funciona a nivel de software? Redes Neuronales
Con respecto al software, la IA se basa principalmente en el uso de algoritmos de redes neuronales. Una red neuronal es un conjunto de nodos (o neuronas) cada uno de ellos caracterizados por una activación a que es un número real. Como se muestra en la Figura 2, estos nodos se encuentran vinculados entre sí mediante una serie de conexiones (o sinapsis) caracterizadas por un número real w que determina el grado de conexión entre las dos neuronas conectadas y que recibe el nombre de peso sináptico.
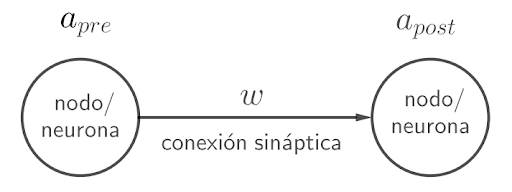
Figura 2: Conexión sináptica entre dos neuronas o nodos de una red neuronal indicando las activaciones a (presináptica a la izquierda y postsináptica a la derecha) y el peso sináptico w.
Para hacernos una idea más concreta, supongamos que queremos construir una red neuronal que sea capaz de diferenciar perros de gatos en imágenes en las que aparece un perro o un gato (véase Figura 3). Es decir, que tenga una serie de neuronas de entrada que lean la información de una foto, posteriormente procese la información y finalmente indique mediante dos neuronas de salida si la foto enseñada corresponde a un perro o a un gato. La idea es que la información de entrada, la foto, se propague a través de la red, neurona tras neurona, hasta llegar finalmente a las dos neuronas de salida1.
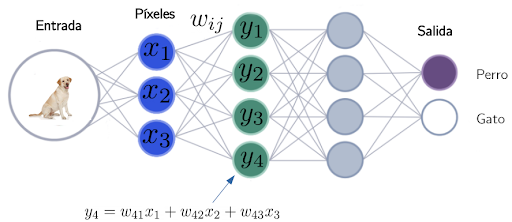
Figura 3: Estructura simplificada de una red neuronal capaz de distinguir perros de gatos. En la parte inferior se indica cómo se computan las activaciones de una capa a partir de las activaciones de la capa anterior.
¿Y cómo se propaga la información? La activación yi de una neurona (que no sea de entrada) se calcula ponderando la activación xj de las neuronas de la capa anterior mediante los pesos wij de las conexiones que terminan en ella, tal y como se muestra en la parte inferior de la Figura 3.
Vale, hemos hablado de que hay unos pesos, pero ¿qué valores tienen? La red no va a funcionar con cualquier tipo de pesos, ¿cómo sabemos cuáles son los pesos adecuados? Aquí viene la "magia". Tú no tienes que preocuparte por el valor de esos pesos, el ordenador prueba de una forma aleatori (aunque optimizada) muchas configuraciones de pesos hasta que encuentra una que es capaz de distinguir perros de gatos decentemente. De este modo, tú no tienes que decidir si tal peso sináptico tiene que valer 4 y el otro -7 para que la red neuronal sea capaz de reconocer si las orejas de la foto son puntiagudas o más redondas; la red neuronal se programa sola. El precio a pagar es que mirando los pesos no sabes muy bien por qué funciona la red neuronal, lo que la convierte en una especie de caja negra a la que se le ofrece un input y la mayoría de las veces devuelve el output deseado.
¿Cómo funciona a nivel de hardware?
Las redes neuronales se implementan actualmente en ordenadores que, como la mayoría de los ordenadores, siguen la denominada arquitectura de von Neumann. Según se muestra en la Figura 4, este diseño está fuertemente caracterizado por la separación en las computadoras de una zona dedicada al cómputo (el procesador o CPU) y otra al almacenamiento de información (las memorias como la RAM o el disco duro). Para implementar redes neuronales en esta arquitectura, se debe desplazar constantemente la información de los pesos y las activaciones de la memoria al procesador para calcular nuevas activaciones, y posteriormente el resultado se ha de trasladar de vuelta a la memoria para su almacenamiento (Figura 4).
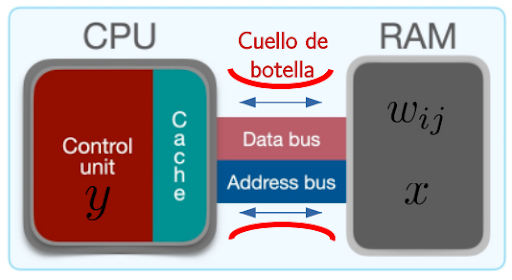
Figura 4: Actual arquitectura de computadores de von Neumann donde el desplazamiento continuo de activaciones x y pesos w entre la CPU y la memoria RAM satura las comunicaciones en lo que se denomina el Cuello de Botella de von Neumann.
Con esta forma de proceder el problema es el siguiente: cuando se implementan las redes más punteras que se utilizan actualmente, con millones de pesos y miles de activaciones, este ir y venir constante de información entre el procesador y la memoria satura las vías de comunicación en lo que se conoce como el Cuello de Botella de von Neumann. Es más, se produce un gran consumo energético debido a todo el calor disipado por efecto Joule al mover la información entre el procesador y la memoria.
Una solución: Mallas de memristores
Si el problema tiene su origen en el hecho de que la memoria y el procesador se encuentran físicamente separados, cabría plantearse diseñar una nueva arquitectura de ordenadores en la que ambas partes se encuentren más próximas o incluso estén fusionadas. Movidos por esta idea, se ha planteado implementar redes neuronales con un nuevo componente electrónico denominado memristor (fruto de la fusión de los términos memoria + resistencia) capaz de combinar en un solo dispositivo memoria y cómputo. Si quieres saber más sobre estos nuevos dispositivos, una maravillosa introducción a los mismos se puede encontrar sin ir muy lejos en este blog [5]. Para poder entender lo que resta de artículo basta que te quedes con lo siguiente:
el memristor es un dispositivo electrónico con dos terminales entre los que el paso de la corriente encuentra una resistencia eléctrica (como en una resistencia convencional) con la peculiaridad de que el valor de esta resistencia depende del historial de corrientes que ha pasado por el memristor, es decir, se trata de una resistencia programable.
Para hacernos una idea más concreta, estos dispositivos se pueden fabricar montando una estructura tipo sándwich con tres materiales: dos placas conductoras o electrodos que encierran en medio un aislante. El aislante tiene la capacidad de formar unos filamentos conductores que permiten el paso de la corriente entre los dos conductores, lo que hace que el sándwich tenga una resistencia eléctrica. De forma crucial, estos filamentos no son estáticos, sino que aplicando corrientes lo suficientemente altas en un sentido u otro es posible destruir o construir estos filamentos y, por tanto, controlar según nuestro deseo la resistencia del sandwich. Todo esto es muy interesante, pero volvamos a lo que nos incumbe: ¿cómo podemos implementar redes neuronales utilizando memristores? Vayamos poco a poco.
Empecemos considerando un único memristor. La corriente que fluye por él vendrá dada por la Ley de Ohm, I = GV, donde </strong></em>G</strong></em> es la conductancia (o la inversa de la resistencia), y V es el voltaje. Esto se encuentra representado en la parte derecha de la Figura 5, donde se ha utilizado el símbolo del memristor. Si comparamos la ecuación anterior con cómo se relaciona la activación de una neurona pre-sináptica apre conectada a una sola neurona post-sináptica con activación apost (parte izquierda en la Figura 5), vemos que el voltaje V podría jugar el papel de la activación pre-sináptica; la conductancia G, el del peso sináptico w; y la intensidad I, el de la activación post-sináptica.
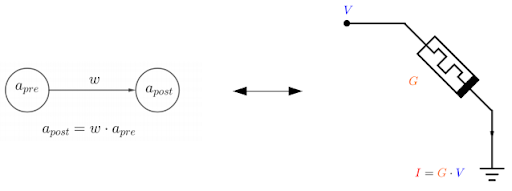
Figura 5: Analogía entre dos neuronas en una red neuronal (izquierda) y un memristor (derecha).
Si combinamos M memristores tal y como se muestra en la Figura 6, la intensidad resultante será la suma. Este esquema nos sirve como el equivalente a M neuronas presinápticas conectadas a una neurona post-sináptica.
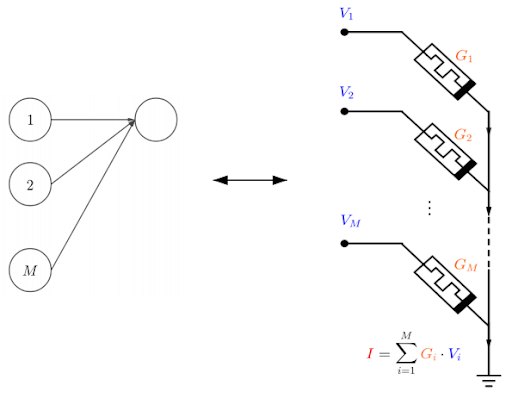
Figura 6: Analogía entre M neuronas conectadas a otra en una red neuronal y M memristores conectados a un punto de tierra común.
¿Cómo completamos nuestra red? Si ahora copiamos esta estructura conectando memristores de forma transversal podemos obtener una malla tal y como la que se muestra en la Figura 7. Este esquema equivale a una red con M neuronas de una capa a N neuronas de otra. Lo importante de usar mallas es que no son estáticas: al estar hechas de memristores podemos programar mediante corrientes las conductancias Gij de modo que repliquen los pesos sinápticos wij que hacen que las redes neuronales lleven a cabo la tarea para la que han sido diseñadas. De este modo, combinando varias de estas mallas una tras otra es posible implementar una red neuronal completa.
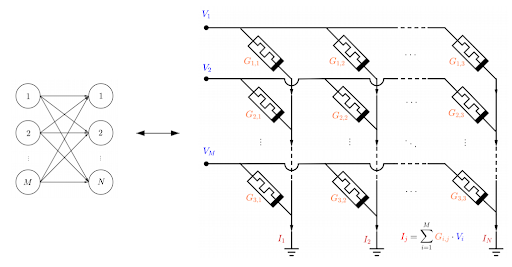
Figura 7: Analogía entre la conexión de M neuronas presinápticas conectadas a N neuronas postsinápticas en una red neuronal y M x N memristores conectados en una estructura de malla.
¿Y cómo determinan estas mallas qué valores de conductancia se han de usar? La respuesta es que estas mallas no son capaces de aprender por su cuenta, solo sirven para inferir, es decir, para computar las respuesta de la red neuronal sabiendo de antemano cuáles son los pesos adecuados. El entrenamiento se realiza fuera de la malla en un ordenador tradicional que determina la configuración óptima de los pesos sinápticos. Posteriormente, estos pesos óptimos se escriben en la malla programando mediante voltajes adecuados los valores de las conductancias de los memristores. Ciertamente hay versiones más complejas de estas mallas que son capaces de realizar también el proceso de entrenamiento [6], pero en este artículo se ha preferido mostrar mallas especializadas en inferencia ya que estas encierran todas las ideas que se pretendía transmitir.
Utilizando estas estructuras se espera aumentar la eficiencia energética en mil veces y la temporal en cien veces [7], lo cual supone un gran avance con respecto a las tecnologías presentes y ofrece una alternativa más sostenible para la implementación de tecnologías basadas en IA. La razón del aumento de la eficiencia temporal se puede prever observando lo siguiente: los ordenadores actuales tienen que realizar las operaciones neurona tras neurona, de modo que el tiempo que les lleva realizar las cuentas crece de forma proporcional al número de neuronas. Por el contrario, en las mallas de memristores, las operaciones están paralelizadas, es decir, al fluir las corrientes por toda la malla a la vez se ejecutan todas las tareas simultáneamente, de modo que el tiempo de cómputo no depende del número de neuronas2.
Conclusiones
Hemos visto que la Inteligencia Artificial esconde unas ineficiencias energéticas y de tiempo de cálculo inaceptables si queremos seguir extendiendo el uso de esta tecnología de una forma sostenible. Esta ineficiencia tiene su origen en que la actual arquitectura de computadores no se adapta bien a la estructura de las redes neuronales y consecuentemente es necesario un costoso desplazamiento constante de información entre las memorias y el procesador. Afortunadamente, desde los campos de la física y la ingeniería se ha ideado una alternativa. Se trata de implementar redes neuronales con unos nuevos dispositivos electrónicos llamados memristores capaces de combinar memoria y procesamiento en el mismo lugar, lo que permite obtener eficiencias energéticas tres órdenes de magnitud superiores a las presentes.
1: Para enseñarle una foto a la red neuronal, cogemos cada uno de los píxeles de la foto y asignamos cada uno de sus valores de intensidad a la activación de una serie de neuronas de entrada (si la foto está en blanco y negro, basta con un valor de intensidad lumínica; si está a color, necesitaremos tres valores).
2: En computación se dice que el proceso que realiza el ordenador, que es proporcional al número de neuronas, tiene una complejidad temporal de orden O(número de neuronas). Sin embargo, en la malla de memristores, la complejidad es O(1), es decir, la complejidad es constante.
Referencias
[1]: Youyou, W., Kosinski, M. and Stillwell, D., 2015. Computer-based personality judgments are more accurate than those made by humans. Proceedings of the National Academy of Sciences, 112(4), pp.1036-1040.
[2]: Strubell, E., Ganesh, A. and McCallum, A., 2019. Energy and Policy Considerations for Deep Learning in NLP. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.
[3]: M. Cho et al. PowerAI DDL. 2017. arXiv: 1708.02188.
[4]: Grabación disponible en [https://youtu.be/vFr3K2DORc8].
[5]: Sergio J Salvía Fernández, 2020. Memristores: ¿neuronas para tu ordenador? Blog del Grupo de Estudiantes RSEF. [https://estudiantes.rsef.es/blog/2020/10/11/memristores/].
[6]: Chang, H., Burr, G., Narayanan, P., Lewis, S., Farinha, N., Hosokawa, K., Mackin, C., Tsai, H., Ambrogio, S. and Chen, A., 2019. AI hardware acceleration with analog memory: Microarchitectures for low energy at high speed. IBM Journal of Research and Development, 63(6), pp.8:1-8:14..
[7]: Marinella, M., Agarwal, S., Hsia, A., Richter, I., Jacobs-Gedrim, R., Niroula, J., Plimpton, S., Ipek, E. and James, C., 2018. Multiscale Co-Design Analysis of Energy, Latency, Area, and Accuracy of a ReRAM Analog Neural Training Accelerator. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 8(1), pp.86-101.